TeSS (Training eSupport System)
TeSS is a platform that was developed to provide a one-stop shop for trainers and trainees to discover online information and content, including training materials, events and interactive tutorials. For training providers, TeSS provides opportunities to promote training events and news, and to contribute to a growing catalogue of materials; for trainers, the portal offers an environment for sharing materials and event information; for trainees, it offers a convenient gateway via which to identify relevant training events and resources, and to perform specific, guided analysis tasks via customised training workflows.
The mTeSS-X Project (Multi-space Training e-Support System with eXchange) overcomes the fragmentation of training resources across Research Infrastructures and the European Science Clusters. The project aims to enhance existing TeSS-based training registries or catalogues like ELIXIR TeSS (life sciences) and PaN-Training (photon and neutron) by building an aggregator for these and similar platforms.
TeSS was originally developed as part of ELIXIR, Europe's distributed infrastructure for life-science data. One of the goals of ELIXIR is to train research scientists to better use available computational infrastructures to address critical research questions. This requires access both to face-to-face training opportunities and to disparate training materials and resources, currently dispersed across Europe.
Events
Events in TeSS are defined as face-to-face or online training opportunities that have set start and end times. These primarily take the form of workshops, courses, webinars, etc.; but TeSS also collects information about conferences, meetings and hackathons, as these may also provide opportunities for learning.
TeSS collects event information from 86 content providers, supplementing the data with geolocation information found using Nominatim.
Discover Events
Materials
Materials in TeSS are defined as training resources that can be accessed at any time. These may be in a variety of different formats, including online tutorials, videos, PowerPoint presentations, and so on.
TeSS collects materials from 81 content providers.
Discover Materials
Training Workflows
New to TeSS are graphical training tools termed 'Training Workflows'. Three main types of workflow are in development: Educational Resources, Learning Pathways and Concept Maps. These encapsulate different types of, and/or approaches to, training, at different levels of granularity, within easy-to-use visual displays.
Learning Paths
In order to advance their skills, trainees need to embark on a path, or developmental trajectory. To facilitate this journey, learning paths aim to structure, within simple visual workflows, the set of relevant training resources that trainees need to study in order to accomplish their learning objectives. Learning paths are being developed by ELIXIR TeSS, ELIXIR-NL and ELIXIR UK.
Discover Learning PathsEducational Resource
In this type of workflow, trainees are introduced to various practical tasks, linked to associated online tools and/or databases, within self-contained modules. Each module includes i) succinct statements of teaching goals and learning outcomes, to convey to trainees what they will be able to do on completion of the module; ii) a series of questions or ‘Reflections’ to provoke critical thinking about the tasks that have been completed; iii) additional background information and further reading to help support learning and enquiry; and iv) multiple choice quiz questions to evaluate understanding at the end. Educational Resources for introductory sequence and structural bioinformatics are currently being developed by ELIXIR TeSS, ELIXIR-UK and the UK Structural Bioinformatics group (via the FunPDBe project).
Discover Workflows
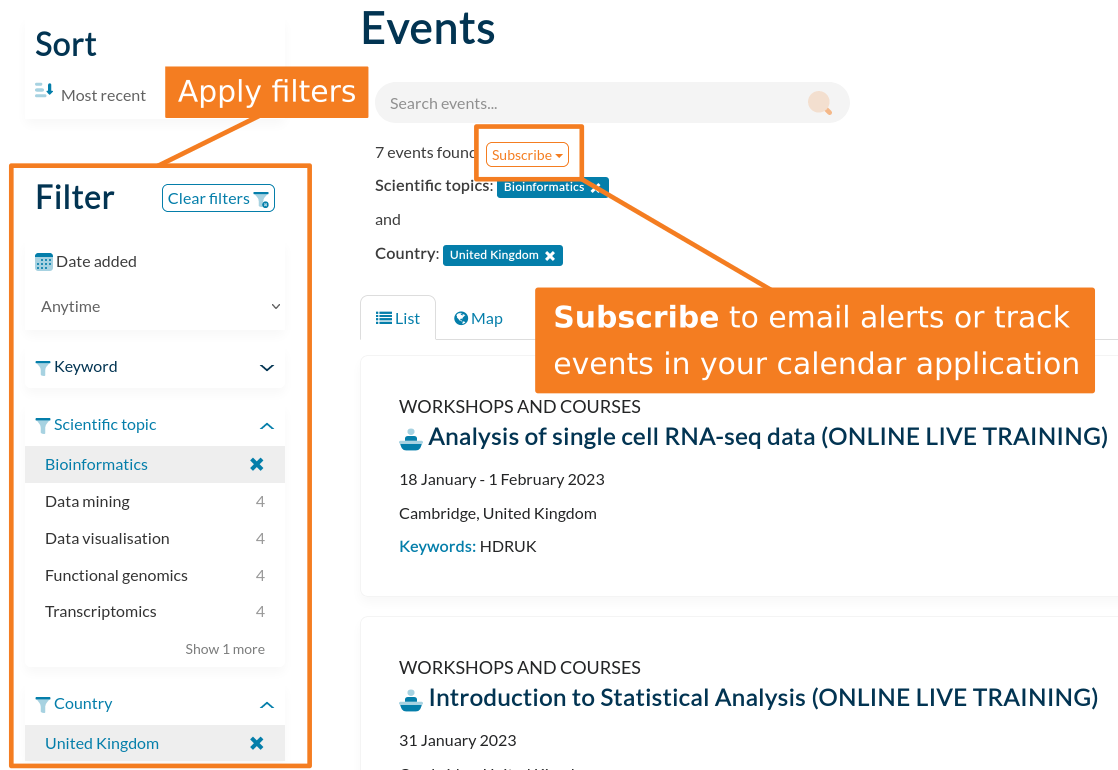
Subscribe
TeSS also provides a subscription feature to help users to stay informed about courses, workshops and conferences of interest to them. The service may be customised by selecting the relevant filters, and initiated via the subscribe button. Users may choose to receive email notifications about upcoming events, or have them automatically added to their preferred calendar application.
The subscriptions manager page may be used to change the frequency of, or to remove, subscriptions.
Widgets & API
To access TeSS data, organisations may readily import information about relevant events and materials to their site using widgets, or may create custom feeds using our API.
Learn more about Widgets Learn more about our API